The quick version:
-
Cloudflare says it blocked 416 billion AI bot requests since last July.
-
Google now crawls about 3.2x more webpages than OpenAI.
-
The scale of AI’s hunger for live web data is reshaping the data-access business I work in.
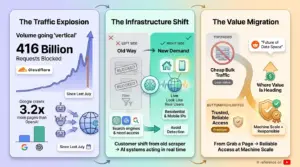
The numbers tell the story
The volume of automated traffic on the web has gone vertical. Cloudflare reports blocking 416 billion AI bot requests since last July, and Google is crawling roughly 3.2 times more pages than OpenAI. Whatever you think of bots, that is the new baseline, and it is only climbing.
https://www.youtube.com/watch?v=UXJd7mlUPTg
What it means for proxies
Every AI system that answers questions about the live web needs to reach that web, and increasingly without getting blocked.
That is pushing demand toward residential and mobile IPs that look like real users, because datacenter ranges get filtered fast. The customer for proxy infrastructure is shifting from the old scraper to AI systems acting in real time.
My read
This is the most interesting moment I have seen in the data space. The work is moving from “grab a page” to “reliably access the web at machine scale, responsibly.”
I keep telling people on Reddit who ask about getting into this field that the future is not cheap bulk traffic, it is trusted, reliable access, and that is where the value is heading.
Quick Links:



